Ask: a better way to dig through your discoveries

Or: how we stopped losing our own insights.
The problem that forced us to build this
We had a pile of insights and nobody could find anything in it.
Here's what actually happened. I ran two discoveries back-to-back against a sample vacation rental dataset we use for testing — a thing called WanderBricks. Two runs, 132 insights between them, a handful of recommendations, seven analysis areas. Normal DecisionBox output. Nothing weird about the numbers.
A few days later I was on a call and someone asked me "didn't one of those runs find something about same-day bookings getting cancelled a lot?" And I genuinely could not remember which run, which analysis area it was under, or what the exact finding said. I opened the dashboard and started clicking through insight cards. It took me about four minutes of scrolling to find it.
Four minutes is the kind of friction where you just stop looking. And if I'm doing that — I wrote the thing — a customer staring at their own dashboard for the first time has no chance.
So we built Ask.
What Ask is (and what it isn't)
Ask is a text box. You type a question in plain English, and it pulls up the insights and recommendations your discoveries already produced that are relevant to what you asked. Then it writes you a short answer that stitches those findings together, with numbered citations pointing back to the originals.
I want to be clear about one thing before going further: Ask does not make things up. It doesn't invent data. It doesn't run new SQL. It doesn't talk to your warehouse. It retrieves existing insights from the runs you've already completed and summarizes them. If you ask it about something the agent never analyzed, it will tell you it has nothing.
If that sounds boring, good. The whole point is that every number in the answer is traceable back to a SQL query the agent wrote and validated against your data. You can click any citation and read the raw insight — name, description, affected count, risk score, source steps, discovery run, timestamp. All of it.
What it actually feels like to use
I'll just walk through the session I ran while writing this post. Same project, same two discoveries, no cherry-picking. All the quotes below are copied from actual answers.
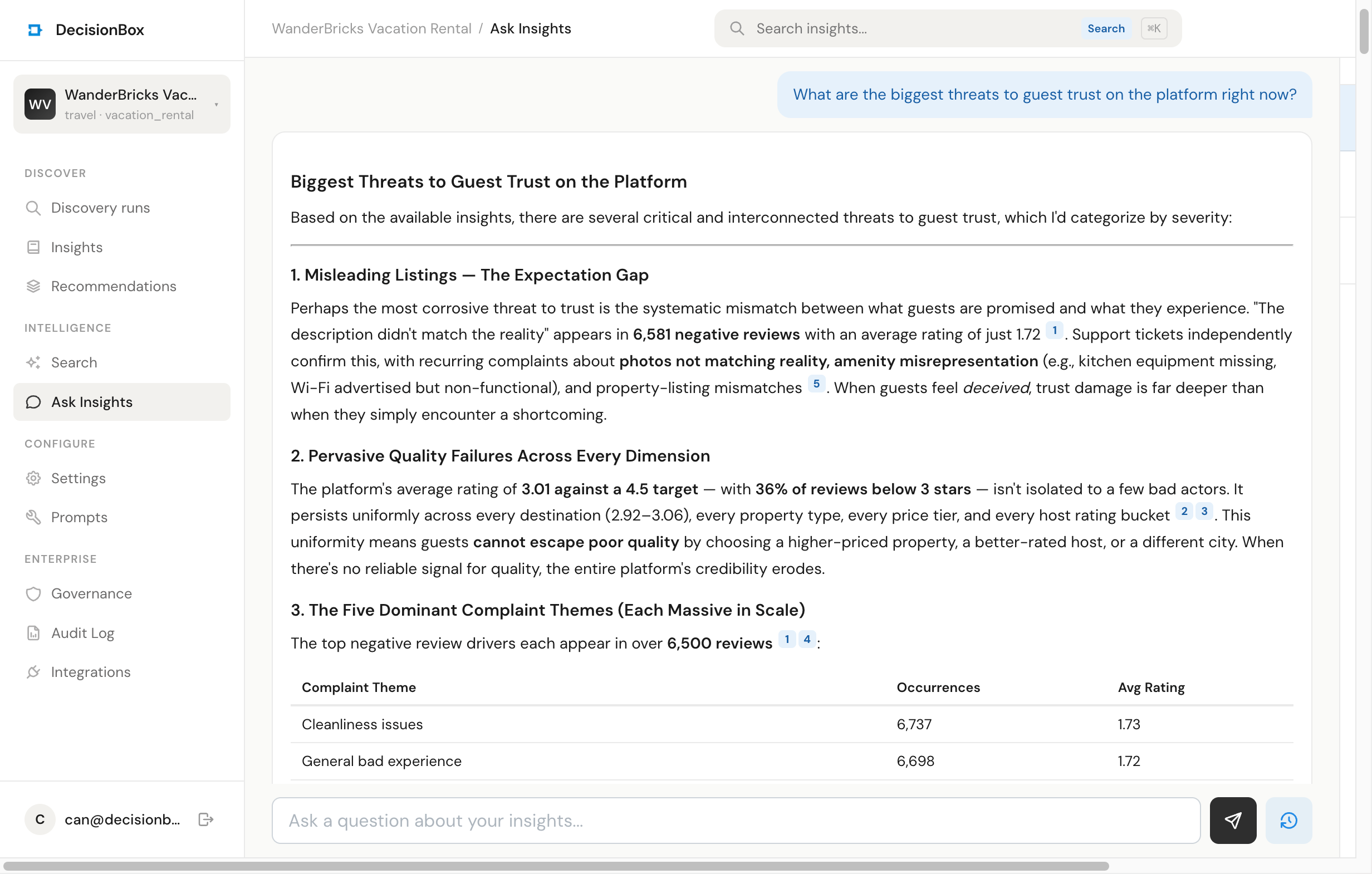
Question 1: "What are the biggest threats to guest trust on the platform right now?"
Six results came back. The top match was an insight about the five dominant negative review themes — cleanliness, maintenance, unresponsive hosts, misleading descriptions, and bad experiences — each appearing in over 6,500 reviews. The second was the platform-wide rating sitting at 3.01 against a 4.5 target. Then support tickets confirming listing-accuracy complaints, then a suspicious 99,793-reviews-against-72,244-bookings ratio that hints at data integrity issues.
The answer pulled those together into one paragraph I'd actually put in a deck:
"A guest who sees a misleading listing, arrives to a dirty property, can't reach the host, and then reads reviews that seem unreliable has experienced a complete trust chain failure. The data bears this out: guests with 1–2 star average experiences have only a 7.35% repeat booking rate versus 25.6% for those with 3–4 star averages."
The 7.35% number is from an insight I hadn't even opened before. Ask found it, cited it, and wove it into the narrative. That's the thing I wanted — a map across insights, not just a list.
Question 2: "Where are we losing the most money? I care about the biggest revenue leaks."
Same session. This is the part where the multi-turn bit matters — Ask remembers what we've already talked about, so follow-ups land naturally.
Top result: cancellation leakage. $5.8M lost in the first seven months of 2025, about 22% of gross. Second result: 77% of guests who cancel never rebook, which is a separate $4.5M annual churn. Third: a refund rate accelerating to 9.3%. The answer arranged these in order of financial impact, which I did not ask for but is obviously what I wanted.
I didn't have to phrase the question a specific way. I didn't have to remember that cancellation findings were in the cancellation and revenue analysis areas. I just said "revenue leaks" and it pulled the right things.
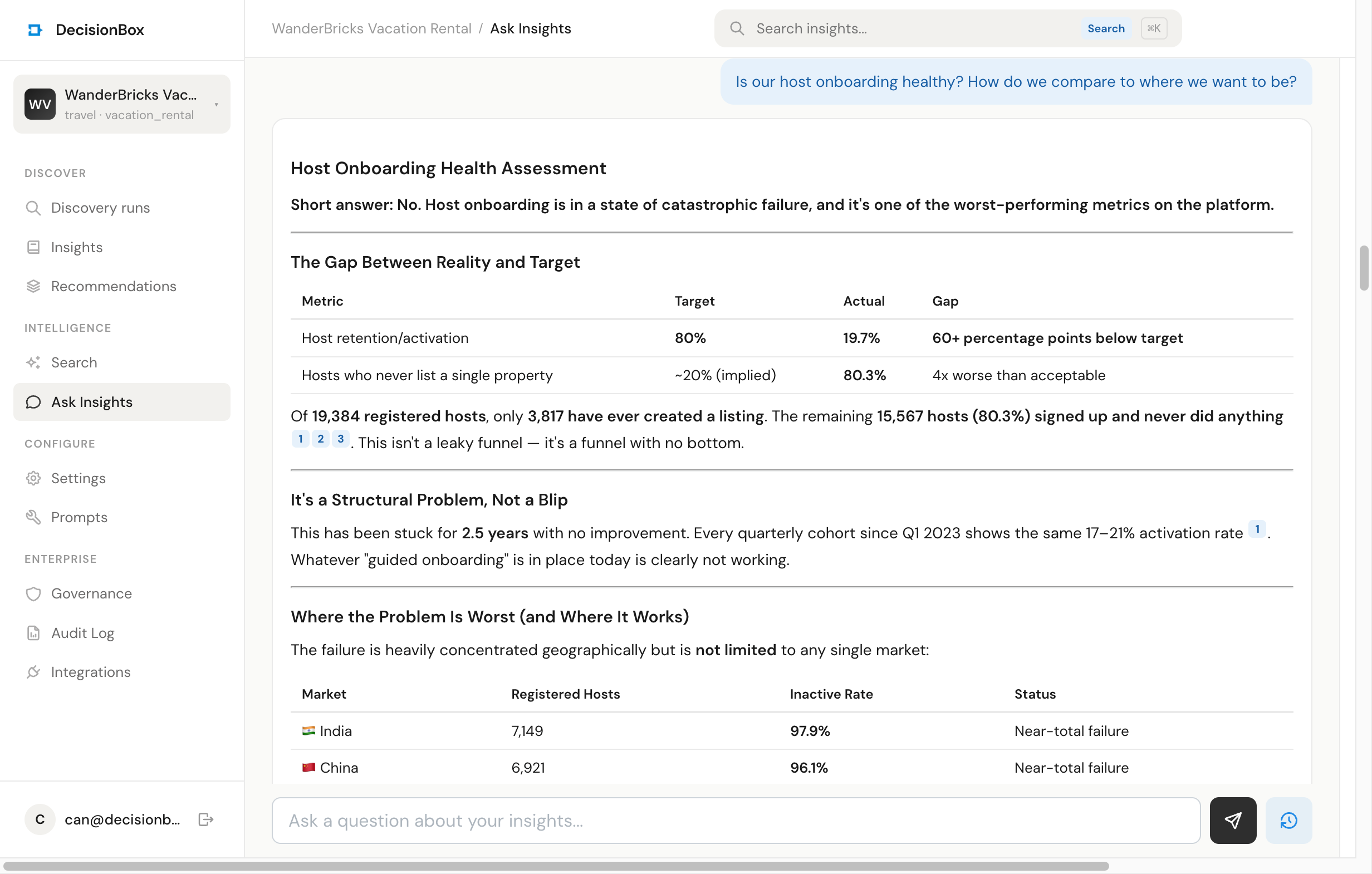
Question 3: "Is our host onboarding healthy? How do we compare to where we want to be?"
This is where I got a bit emotional because the answer was really good.
It opened with:
"Short answer: No. Host onboarding is in a state of catastrophic failure, and it represents one of the most severe underperformance gaps on the platform."
Then a table — 80% target, 19.7% actual, 60-point gap. Then the absolute counts: 19,384 registered hosts, 3,817 have ever created a listing, 15,567 signed up and did nothing. Then a country-by-country breakdown showing that India and China together account for 72.6% of registered hosts and only 2.96% of them have listed anything. Then a first-week retention window — hosts who list within a week average 6.8 properties and 17.3 bookings, hosts who take six months average 2.9 and 8.3.
Every one of those numbers came from a different insight in the discovery run. I could have found them manually. I would not have thought to line them up next to each other like that.
Question 4: "Out of everything above, what could we actually ship this quarter to move the needle?"
This is the question I care about most, because "what do I do on Monday" is the real job. The answer came back with four concrete initiatives, ordered by impact and effort, with dollar ranges attached:
- Same-day booking guardrails — non-refundable deposits for bookings made within 3 days of check-in. Estimated $800K–$2M saved in cancellation losses this quarter, based on the insight that 26.4% of July volume came from same-day bookings with a 40.8% cancel rate.
- Mega-host relationship program — defensive, protects the $8.18M (31% of platform) concentrated in the top 169 hosts. Low-medium effort.
- Off-season activation for 7,068 summer-only properties — the agent had already found that 39% of supply has literally zero bookings outside June-July. Ask stitched that to a recommendation the agent generated in the same run.
- Urban destination acceleration — longer-term, but addresses the Q4/Q1 seasonal cliff.
It also added a "what I'd explicitly deprioritize" section that basically said: don't bother with pricing optimization this quarter, the structural problem is too big for a one-quarter fix. I didn't ask for that. It just did it.
The thing I want you to notice is that #3 cited both an insight ("Summer Seasonal Destinations Surge 135-217% Q1-to-Q2") and a separately-generated recommendation ("Launch Off-Season Activation Campaign"). Ask treats insights and recommendations as the same kind of thing for retrieval — they both get embedded, they both get searched, they both get cited. That matters when you're trying to answer "what should we do" because the agent already did that work in a previous run. You just need to be able to find it again.
The search is the thing
I want to call out one specific query because it surprised me.
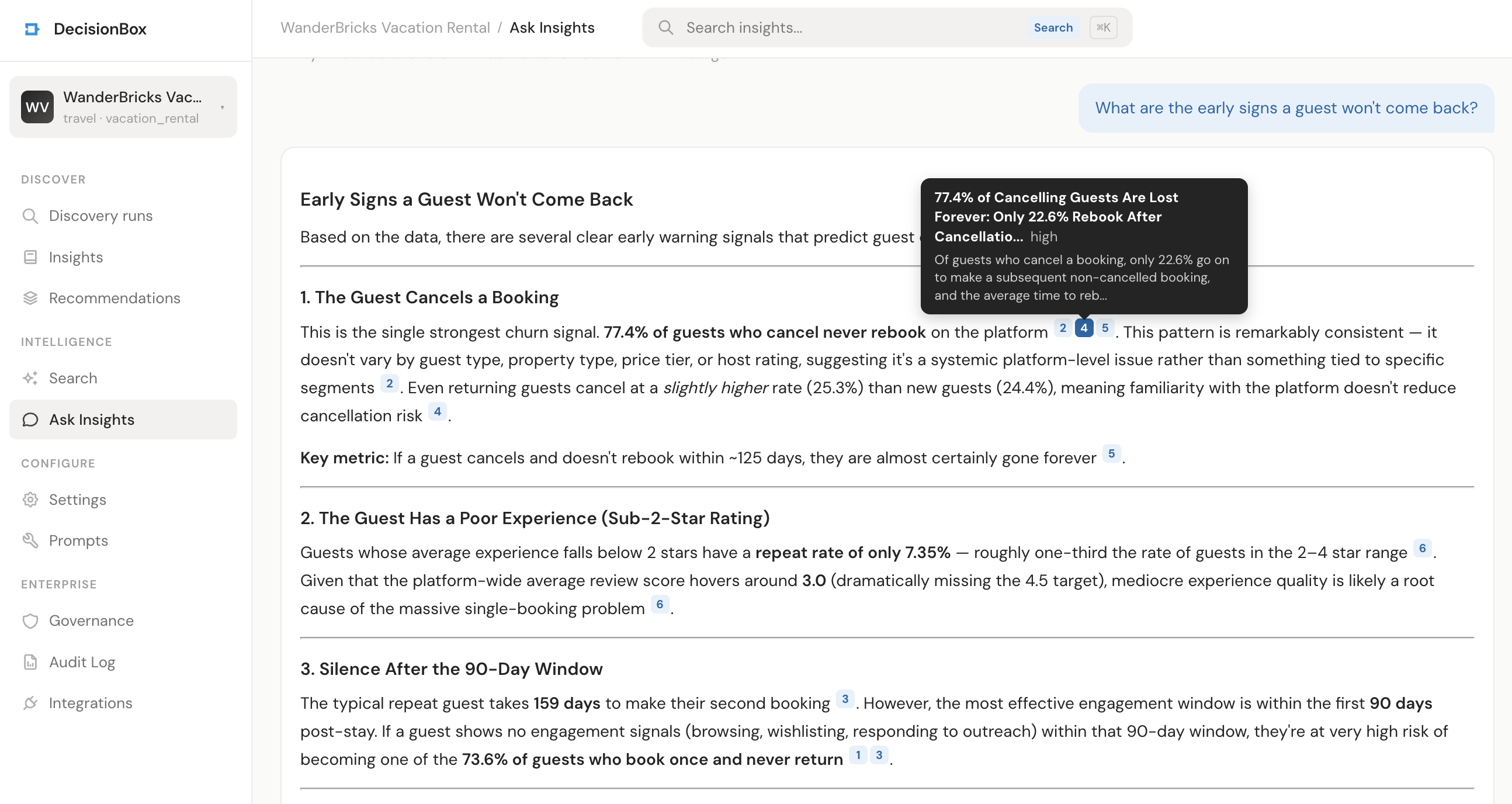
In a fresh session I asked: "What are the early signs a guest won't come back?"
None of the matched insights contain the phrase "early signs" or "won't come back" in their titles. What came back:
- 73.6% Single-Booking Guest Rate: 40,242 Guests Never Return
- 77% of Guests Who Cancel Never Rebook
- Two-Booking Guests Take 159 Days to Return
- Low-Rated Experiences Drive Churn: Guests With <2-Star Average Have Only 7.35% Repeat Rate
That's a semantic match, not a keyword match. The insight titles talk about "repeat booking," "rebook," "return," "retention." My question talks about "early signs" and "won't come back." Different words, same concept. The embedding model — text-embedding-3-large, in our case — handles that without anyone having to think about it.
The reason this matters: you don't have to remember how the agent phrased a finding to get back to it. You just have to remember roughly what it was about. Which is how humans actually remember things.
How it works under the hood
Short version for the people who care.
When a discovery finishes, every insight and every recommendation gets embedded and stored in a vector database. We use Qdrant (which now ships as part of the default deployment). The embedding model is pluggable — OpenAI text-embedding-3-large is the default, but you can point it at whatever provider you prefer. The same provider abstraction we already have for LLMs and warehouses.
When you ask a question, here's what happens:
- Your question gets embedded with the same model.
- Qdrant returns the top-k nearest insights + recommendations by cosine similarity, filtered to your project so one customer can never see another customer's data.
- The top results get passed to the LLM with a prompt that says: answer the user's question using only these sources, cite them like
[1],[2], and if the sources don't cover the question, say so. - The answer and the list of raw sources come back together. The dashboard renders them side by side.
Multi-turn conversations work by replaying the last ten messages from the session as context, so the LLM knows what "that" and "above" and "those" refer to. Sessions belong to a specific project. They're stored in MongoDB alongside everything else. There's no separate infrastructure.
One thing worth saying: we use the same LLM provider you've already configured for discoveries. If you're running Claude Opus via Bedrock, that's what answers your questions. If you're running Ollama locally, that's what answers them. No new API keys, no new billing, no new secrets. That was a deliberate call — we didn't want Ask to require a "now also sign up for X" moment.
What it doesn't do
Worth being explicit about the edges:
It doesn't write new SQL. If you ask it a question that isn't covered by your existing discoveries, you'll get a polite version of "I don't have data on that." The fix is to run another discovery, or add a new analysis area to your domain pack.
It doesn't cross projects. Each Ask session is scoped to one project. This is a privacy boundary — it's not something we'll loosen. If you need cross-project reporting, that's a different feature.
It doesn't replace the insights tab. If you're exploring, browse the insights directly. If you have a specific question, use Ask. They do different jobs.
It doesn't know about the future. It knows what your discoveries found, which is a snapshot of what your data looked like when the run happened. "What will happen next quarter" isn't a question it can answer, and it will tell you so.
How to try it
If you're already running DecisionBox, pull the latest images and you'll get Ask automatically. The feature is part of the community release, AGPL v3, runs in your own infrastructure, no separate tier. You'll need Qdrant running, which the Helm chart provisions by default.
- Navigate to a project with at least one completed discovery
- Click the Ask tab in the sidebar
- Type a question
That's it. There's nothing to configure. Your existing discoveries are already indexed on run completion — no backfill step, no migration, no "enable this feature" toggle.
If you don't have a project yet: pick a domain pack, connect a warehouse, hit run. Come back in ten minutes and start asking questions.
Where we're taking it
A few things on the list. No promises on timing.
- Cited chart generation. When an answer references a trend over time, draw it. The data is already in the insight metrics, we just need to render it.
- Saved questions. Right now every session is free-form. Eventually you should be able to save "the five questions I check every Monday" and have them run against each new discovery automatically.
- Cross-discovery comparison. Right now a single question retrieves across all discoveries in a project, which is usually what you want. But being able to scope explicitly to "compare last week's run to this week's" is the obvious next step.
- Slack integration. Ask, but from the place where the question actually gets asked.
One last thing
The reason I wrote this post the way I did is that I'm a bit allergic to the way AI features get talked about right now. "Revolutionary AI-powered conversational insights experience" — you can find that sentence on a dozen product landing pages this week and none of them mean anything.
Ask is a text box that helps you find stuff you already have. It's useful because the alternative is scrolling through 132 insight cards trying to remember which one had the 7.35% number. That's all it is. That's enough.
If you try it and it doesn't help, tell us what question it fell over on. That's the useful feedback. The email is can@decisionbox.io, or open an issue on the repo.
— Can