Control exactly what
the AI can see.
Protect sensitive data without rewriting your warehouse schema or ETL pipelines. Classify columns once, and DecisionBox enforces it everywhere — from the query planner to the final report.
Three layers of protection
Schema filtering
Columns tagged as PII or restricted never enter the AI's context. The agent can't query what it doesn't know exists.
AI query rewriting
If a model ever tries to SELECT a sensitive column, the query is automatically rewritten or refused before execution.
Result-level redaction
Any sensitive value that slips through returns as [REDACTED] in query results and downstream insights.
From raw to redacted in four steps
| user_id | region | amount | |
|---|---|---|---|
| u-4821 | j@ac.co | US-West | $142.00 |
| u-7733 | m@co.io | EU-North | $89.50 |
| u-1094 | s@in.co | US-East | $215.75 |
| u-5507 | l@fi.co | APAC | $64.20 |
Policies that travel with your data
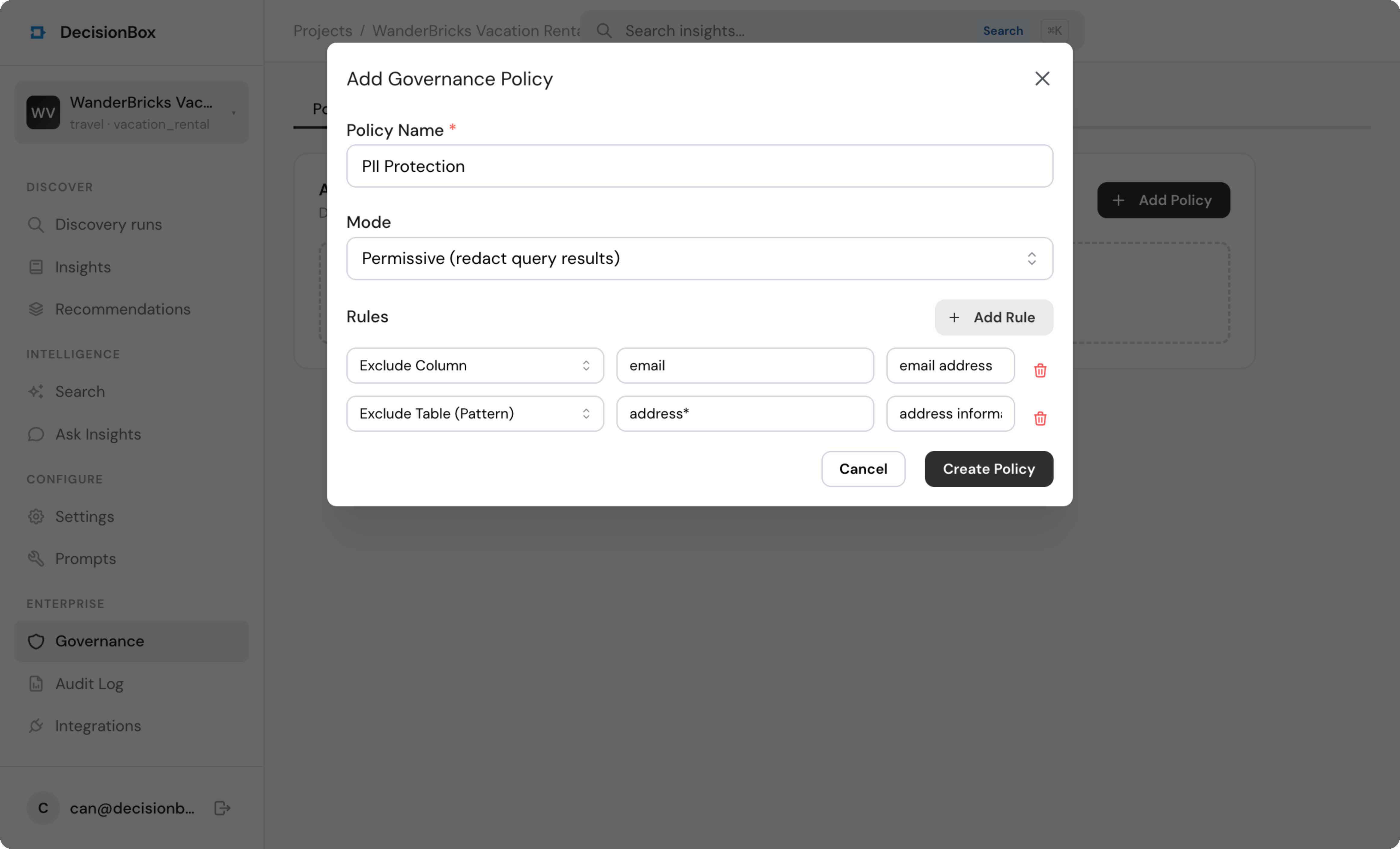
Granular access policies
Exclude datasets, tables, or columns using exact match, glob patterns, or regex — no changes to your warehouse schema.
Data classifications
Tag columns as PII or restricted for automatic exclusion. Safe, internal, and confidential levels for policy decisions.
Governance audit trail
Every exclusion decision is recorded with a timestamp, rule, and affected data — ready for compliance reviews.
No single layer is enough.
Schema filtering is prevention. Query rewriting catches anything the model still attempts. Result redaction is the last line of defense. Together they make it physically impossible for sensitive values to leave your warehouse inside an insight, a recommendation, or a chat response.